AI Powered Text to Speech Converter
Crea voces realistas para cualquier texto en segundos usando
over +840 realistic voices across +135 languages & dialects.
Powered By




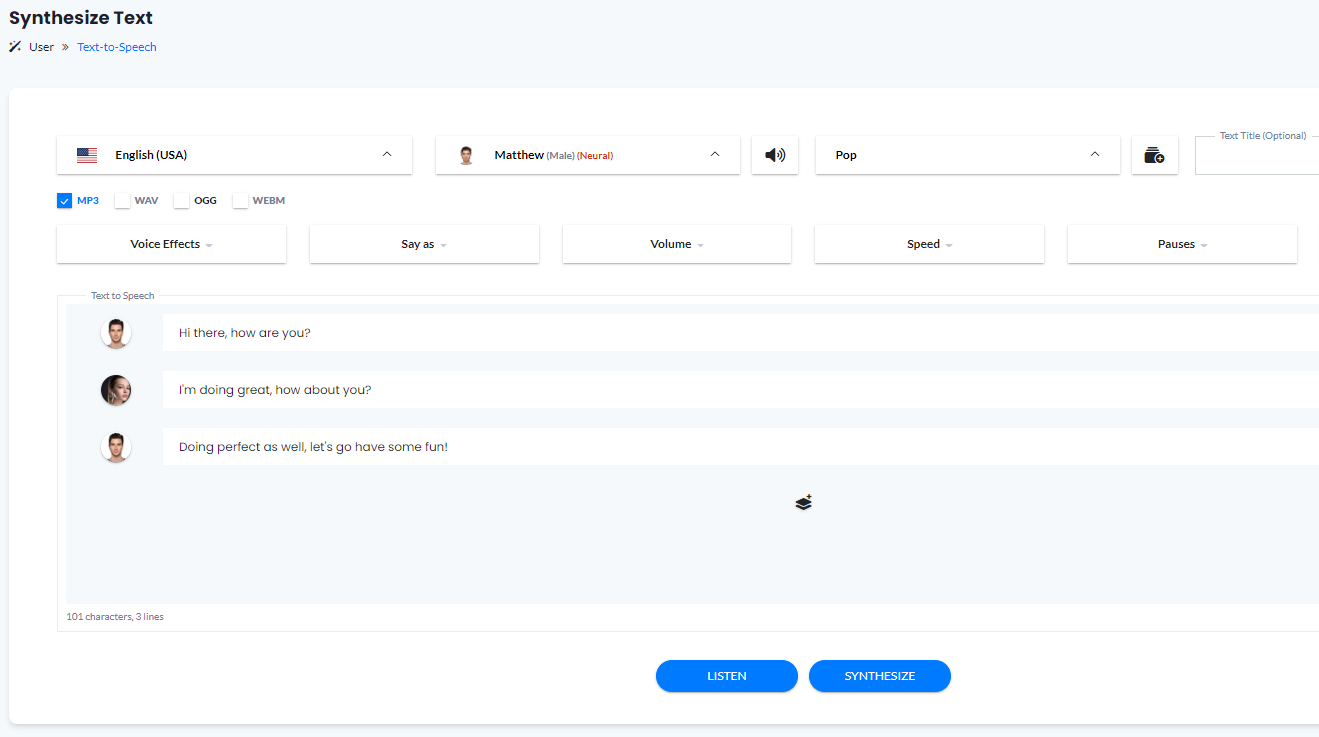
Experience AI Voices
Try out live demo without logging in, or login to enjoy all SSML features
Text to Speech Beneficios
Disfrute de la flexibilidad total de la plataforma con un montón de funciones
Over +840 Voices
Full set of Speech Synthesis Markup Language (SSML) Features
Varios formatos de audio
Over +135 Languages & Dialects
Download & Share Results Easily
Voces estándar y neuronales
Accurately convert text to speech powered by leading
Cloud AI Technologies
Best text to speech converter offering a wide range of customization options so that you can fine-tune the speech to match your specific needs, with the power of leading Cloud AI technologies such as Amazon AWS, Google Cloud Platform, and Microsoft Azure.




































More than +840 voices across
+135 languages and dialects
The list of languages is constantly updated. In addition,
the synthesis of existing languages is constantly being
updated and improved.
Why Escadata TTS?
Text to Speech Blogs
Read our unique blog articles about various text to speech use cases and secrets


Introduction to Escadata Text to Speech Converter | Escadata TTS
October 14, 2022

Convert Text to Speech Powered by Leading Cloud AI Technologies | Escadata TTS
October 14, 2022

Standard Voices vs. Neural Voices - Which should I Choose? | Escadata TTS
October 14, 2022
Frequently Asked Questions
Got questions? We have you covered.